


Scaling Data Governance without falling into the Data Mesh trap
#24 Beyond the Hype

Hello 😀
Like I said on LinkedIn : I love how Data people change their minds every 6 months. (and it's ok, it shows the ability to question oneself)
Data mesh was the revolution, and then... no.

Get my Data Governance templates
Discover my consulting services
Join +230 readers of “Data Governance : where to start?”
Follow me on Linkedin and Twitter
Let’s see how we can scale 👇
Agenda
The Data Mesh trap
It’s all about balance
Scale-up with a marketplace
The Data Mesh trap
You all know the founding article of Data Mesh by Zhamak Dehghani. The promise of Data Mesh is autonomy of domains.
To reach this state, you’ll need to define your domains, create multi-disciplinary teams that can deliver data products on their own relying on infrastructure-as-a-service provided by IT. A data mesh emphasizes a domain-oriented, self-service design.
Honestly this requires super smart AND skilled people. Let’s face it, in most companies today this is strictly impossible.
What happens usually :
Mapping of domains takes months and never ends
Some domains are created but rely on the Data team to deliver data products
To enable self-service and pretend the organization is doing Data Mesh, the Data team will start giving licences to dataviz tools to all business users asking for it
IT will say stop when they realize that costs are exploding
Everything is back to normal, meaning back to the centralized approach
Why is this happening?
Because without governance, autonomy turns into anarchy.
It’s all about balance
It is always really hard to find the sweet spot between autonomy and control. The key is to enable teams while maintaining alignment and trust.
Cool, but how?
Coming back to the mapping of domains. You don’t have to map ALL domains before starting. Map the most obvious ones (usually the most mature) and start from there.
A central Data Governance team will be required to do this mapping, but also to setup guardrails for all domains. I used to think that this central team could disappear over time, but this will be in a lonnnnng time 😈 when we have reached a very high degree of maturity.
With the first domains, you can :
👥 Define data ownership & stewardship – Every domain should have clear roles: Who creates? Who validates? Who maintains?
Help the domain defining these roles and responsibilities with a RACI matrix, and make sure they will be valid for all domains.
🔍 Set clear rules for critical data assets – Define the business definitions and rules for quality but allow flexibility where needed.
Example : if a data asset like a metric is used by 2 domains, allow to have 2 different definitions so they can have their own specificities.
💡 Enable self-service with guardrails – Give domain teams the autonomy to progressively use and share data assets while providing governance tools that make compliance seamless.
In an ideal world, each data asset (a dataset, a visualisation, an analysis, etc.) must be :
shared to be reusable across domains,
with complete metadata
and access rules.
Scale-up with a marketplace
😈 Mh ok, but helping all domains is going to require a lot of effort from the central Data Governance team, no?
Good point. Imagine a “Data Product Marketplace”, where trusted, high-quality data is accessible and reusable across teams.
Wait, what?
A data marketplace is a platform that enables organizations to publish, discover, and exchange data assets in a structured and governed way.
It functions like an online store for data, where users can browse, request, and access data assets whether internally within a company or externally between organizations.
You can learn more here with a guide from Opendatasoft :
A governed data marketplace should include :
✔️ Discoverable & certified data products with clear ownership
✔️ Embedded quality checks & compliance monitoring
✔️ Access control policies that ensure security without friction
✔️ Collaboration & feedback loops so data assets improves over time
Why it can give an answer to the Data Mesh trap :
Teams can manage their own data assets in autonomy while following global governance standards set at an organizational level :
Every business user can publish data assets as long as they complete metadata required and respect global standards.
Different business units can discover and access trusted data assets without bottlenecks caused by excessive IT intervention.
Access controls ensure that only authorized users can retrieve sensitive data.
Quality indicators and usage metrics help users assess whether the data asset meets their needs.
How’s that different from a data catalog?
Let’s see some key differences :
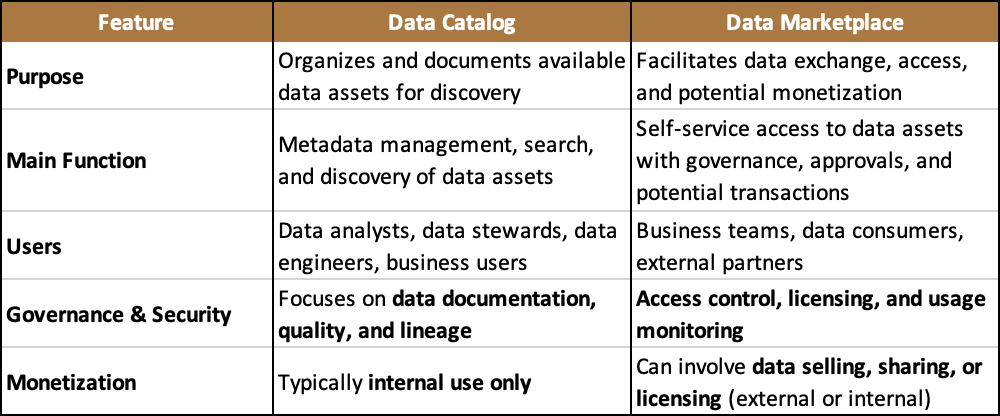
💡You know I love analogies when it comes to understanding concepts :
A data catalog is like a library index : it tells you what books (data assets) exist, where to find them, and their details.
A data marketplace is like an online bookstore : it lets you not only browse books but also request, borrow, or even buy them.
👉 Overall the data marketplace allows self-service access with controls.
See you soon,
Charlotte
I'm Charlotte Ledoux, freelance in Data & AI Governance.
You can follow me on Linkedin !
Thanks for your excellent post about important topic. It reminds me of my thoughts when I first came across the term just before Covid in 2019. I mentioned to the lead engineers that it seemed like a mix of old data management best practices, but there were many misunderstandings and some clearly wrong statements.
One major issue was the confusion around decentralization versus centralization, and governance versus implementation. Some claims were incorrect and led to more chaos, just as you described.
Fortunately, Zhamak wrote a book that offers a more updated view on the topic and best practices. However, many people still read inconsistent blogs and guidelines from different vendors online. One of my favorite parts of the Data Mesh book is this:
"Data product owners are the long-term owners of the domains’ data products. They intrinsically care about the longevity and success of their data product as a member of the mesh. They have accountability for the security, quality, and integrity of their data. Given the guiding principle of executing decisions locally, the data product owners are ultimately accountable for making sure the global governance decisions are executed at the level of every single data product. Early buy-in and contribution of domains to define the global policies is crucial in adoption of them."
This shows that, according to its founder, Data Mesh does include global centralized data governance, as suggested by traditional data management practices. Decentralized teams must follow centralized data governance, which is what makes it a mesh instead of a mess.
In conclusion, a lot of the confusion around Data Mesh comes from a lack of understanding of data management practices and what Data Mesh really means, as intended by Zhamak and others. It is often presented only as a decentralized approach, overlooking the important role of centralized global data governance. Yet, Data Mesh should always have a strong centralized data governance as required by international laws and data management best practices. Its not meant to be a data silo approach.
Sami Laine, Senior Advisor, Aalto EE.